inesdata-ml-schema
A repository to keep the vocabulary for datasets and models developed in Inesdata project. The goal is to have a lightweight vocabulary with a model-centric view of ML models. The vocabulary extends schema.org and Codemeta.
This vocabulary aims to be compatible with the efforts from the FAIR4ML RDA community which are under discussion.
- Authors: Daniel Garijo, Patricia Martin-Chozas, Carlos Ruiz
- License: Apache 2.0
- Version: 0.0.1
- Status: Draft
- Latest version URI:
https://w3id.org/inesdata# - This version URI:
https://w3id.org/inesdata/0.0.1# - prefix:
ind - Date: Dec 28th, 2023
Overview
The following diagram shows the classes, properties and data properties of the inesdata ml schema. Note that a union has been used for classes like author and funder to denote that the domain/ranges includes both classes.
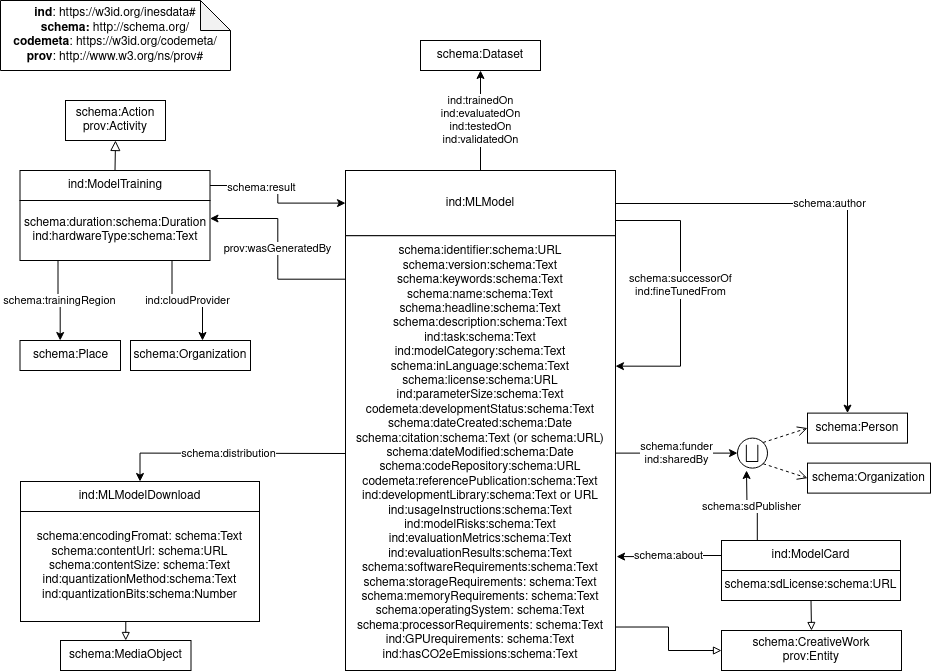
Prefixes used in this document
codemeta: https://w3id.org/codemeta/ind: https://w3id.org/inesdata#prov: http://www.w3.org/ns/prov#schema: http://schema.org/rdfs: http://www.w3.org/2000/01/rdf-schema#
Classes
The classes for the InesDATA machine learning schema are defined below. SubClassOf stands for rdfs:subClassOf. Likewise, domain and range stand for rdfs:domain and rdfs:range.
Machine Learning Model Download (ind:MLModelDownload)
Class representing a downloadable ML model object (models may be distributed in different sizes and quantizations)
- SubClassOf schema:MediaObject
Model Card (ind:ModelCard)
Class aimed at representing metadata records for ML models.
- SubClassOf schema:CreativeWork
- SubClassOf prov:Entity
Executable Machine Learning Model (ind:MLModel)
Class to represent Machine Learning models that can be run for some task (e.g., those available in HuggingFace). A Machine Learning model may have more than one model distribution
- SubClassOf schema:CreativeWork
- SubClassOf prov:Entity
Model Training Activity (ind:ModelTraining)
Action/Activity identifying that a model was trained, and its circumstances (training hours, hardware used, etc.)
- SubClassOf schema:Action
- SubClassOf prov:Activity
Properties
cloud provider (ind:cloudProvider)
Organization who provided the cloud infrastructure to train the model (e.g., Amazon)
- Domain: ind:ModelTraining
- Range: schema:Organization
evaluated on (ind:evaluatedOn)
Dataset used for evaluating the model. The dataset used for evaluation may not have been part of the train/test/validation (e.g., a benchmark)
- Domain: ind:MLModel
- Range: schema:Dataset
evaluation metrics (ind:evaluationMetrics)
Description of the metrics used for evaluating the ML model
- Domain: ind:MLModel
- Range: schema:Text
evaluation results (ind:evaluationResults)
Description of the evaluation results obtained from the model (comparison, metric tables, etc.)
- Domain: ind:MLModel
- Range: schema:Text
fine tuned from(ind:fineTunedFrom)
Relationship to point to the source model used for fine tuning (if this model was finetuned from another one)
- Domain: ind:MLModel
- Range: ind:MLModel
GPU requirements (ind:GPURequirements)
Description of the GPU requirements needed to run the model
- Domain: ind:MLModel
- Range: schema:Text
hardware type (ind:hardwareType)
Description of the type of hardware used when training the model, so it can be used to report emissions.
- Domain: ind:ModelTraining
- Range: schema:Text
has CO2e emissions (ind:hasCO2eEmissions)
Amount of CO2 equivalent emissions produced by the model. The unit should be included in the field (e.g., 10 tonnes)
- Domain: ind:MLModel
- Range: schema:Text
model category (ind:modelCategory)
Category of the model (e.g., SVM, Transformer, Supervised, etc.)
- Domain: ind:MLModel
- Range: schema:Text
model risks(ind:modelRisks)
Description of the risks and biases of the model, in a human-readable manner
- Domain: ind:MLModel
- Range: schema:Text
parameter size(ind:parameterSize)
Brief description on the parameter size used to train the model (e.g., 7B). The unit (e.g., billions) must be included in the description
- Domain: ind:MLModel
- Range: schema:Text
shared by(ind:sharedBy)
Person or Organization who shared the model online (e.g., uploading it to HuggingFace)
- Domain: ind:MLModel
- Range: schema:Person or schema:Organization
tested on(ind:testedOn)
Link to the dataset used to test the model (following train/test/validation splits)
- Domain: ind:MLModel
- Range: schema:Dataset
task (ind:task)
Task for which the model was trained or fine tuned. E.g., image classification, sentiment analysis, etc.
- Domain: ind:MLModel
- Range: schema:Text
trained on (ind:trainedOn)
Link to the dataset(s) used for training the model.
- Domain: ind:MLModel
- Range: schema:Dataset
training region (ind:trainingRegion)
Region where the training of a model took place (e.g., Europe, UK, etc.)
- Domain: ind:MLModel
- Range: schema:Place
usage instructions (ind:usageInstructions)
Description of the instructions needed to run the model (e.g., to do inference on a task). Code snippets may be used for illustration
- Domain: ind:MLModel
- Range: schema:Text
validated on (ind:validatedOn)
Link to the dataset used to validate the model. Typically the training dataset is a separated set from the train/testing set.
- Domain: ind:MLModel
- Range: schema:Dataset
quantization method (ind:quantizationMethod)
Method used for quantizing the distribution of a model. Quantization is often needed to reduce the size of a large language model.
- Domain: ind:MLModel
- Range: schema:Text
quantization bits (ind:quantizationBits)
Number of bits used for model distribution quantization. E.g., 2 bits.
- Domain: ind:MLModel
- Range: schema:Text